Redes Neuronales en Python
En el mundo actual, las redes neuronales son una herramienta esencial en el ámbito del deep learning y la inteligencia artificial. ¿Te has preguntado cómo construir una red neuronal desde cero utilizando Python? Este tutorial te guiará paso a paso, desde la instalación de las herramientas necesarias hasta la implementación y evaluación de un modelo práctico. Ya seas principiante o experto, aquí encontrarás todo lo que necesitas para dominar las redes neuronales en Python. ¡Sigue leyendo y descubre cómo transformar datos en soluciones inteligentes!
¿Qué son las redes neuronales?
Las redes neuronales son modelos computacionales inspirados en el cerebro humano que forman la base del deep learning. Están diseñadas para reconocer patrones complejos y realizar tareas como clasificación y predicción. Estas redes consisten en capas de neuronas artificiales que procesan datos de entrada a través de conexiones ponderadas.
Si deseas profundizar en este tema, te invitamos a descargar la guía que hemos preparado especialmente para ti:
Aplicaciones de las redes neuronales en la IA con Python
Las redes neuronales, impulsadas por Python, están transformando numerosas industrias con aplicaciones innovadoras y eficaces:
- Reconocimiento de voz y habla: Asistentes virtuales como Siri y Alexa utilizan redes neuronales para comprender y responder a comandos de voz.
- Visión por computadora: En el diagnóstico médico, se emplean para identificar enfermedades a partir de imágenes.
- Sistemas de recomendación: Plataformas como Netflix y Amazon analizan el comportamiento del usuario para sugerir contenido personalizado.
- Detección de fraudes: En el sector financiero, las redes neuronales ayudan a identificar transacciones sospechosas y prevenir fraudes.
- Traducción automática: Herramientas como Google Translate utilizan modelos de redes neuronales para proporcionar traducciones precisas y contextuales.
Python, con sus potentes bibliotecas como TensorFlow, Keras y PyTorch, facilita la creación y entrenamiento de estos modelos, permitiendo a los desarrolladores implementar soluciones de IA avanzadas de manera eficiente.
Herramientas y Bibliotecas Necesarias
Instalación de Python
Para comenzar, asegúrate de tener Python instalado en tu sistema. Puedes descargar la última versión desde el sitio oficial de Python.
TensorFlow y Keras
TensorFlow y Keras son bibliotecas populares para desarrollar redes neuronales. TensorFlow es un framework de código abierto de Google, y Keras proporciona una interfaz de alto nivel para facilitar su uso.
Scikit-learn y PyTorch
Scikit-learn es útil para el preprocesamiento de datos y algoritmos de machine learning básicos. PyTorch, desarrollado por Facebook, es conocido por su flexibilidad y eficiencia en la investigación de redes neuronales.
En nuestro artículo sobre librerias de python, aprenderás sobre todas ellas y cómo instalarlas.
Construcción de una Red Neuronal desde Cero
Estructura de una red neuronal
Una red neuronal típica se compone de tres tipos de capas:
- Capa de entrada: Recibe los datos de entrada.
- Capas ocultas: Procesan la información a través de varias capas intermedias.
- Capa de salida: Produce la salida final.
Funciones de activación
Las funciones de activación introducen no linealidad en el modelo, permitiendo que la red aprenda y represente relaciones complejas. Las funciones más comunes son:
- Sigmoide: Transforma las entradas en valores entre 0 y 1.
- ReLU (Rectified Linear Unit): Activa valores positivos y suprime los negativos.
- Tangente hiperbólica (tanh): Similar a la sigmoide, pero sus salidas varían entre -1 y 1.
Comparación de funciones de activación

Entrenamiento de la Red Neuronal
Algoritmo de backpropagation
El backpropagation es un algoritmo de aprendizaje que ajusta los pesos de la red para minimizar el error de predicción. Funciona calculando el gradiente del error con respecto a cada peso utilizando la regla de la cadena, y luego actualiza los pesos en la dirección opuesta al gradiente.
Descenso de gradiente
El descenso de gradiente es un método de optimización que ajusta los pesos para minimizar la función de coste. Existen variantes como el descenso de gradiente estocástico (SGD) y el descenso de gradiente con momento, que mejoran la eficiencia y convergencia.
Función de Coste y Optimización
La función de coste mide la diferencia entre las predicciones de la red y los valores reales. Minimizar esta función es esencial para mejorar la precisión del modelo. Algunas de las funciones de coste más comunes son:
- Error cuadrático medio (MSE): Utilizado principalmente en problemas de regresión.
- Entropía cruzada: Común en problemas de clasificación.
Pasos del Entrenamiento
- Inicialización de Pesos: Los pesos iniciales de la red se asignan aleatoriamente.
- Propagación hacia Adelante: Los datos de entrada se pasan a través de la red para obtener una predicción.
- Cálculo del Error: Se calcula el error comparando la predicción con la salida deseada.
- Backpropagation: Se ajustan los pesos utilizando el gradiente del error.
- Actualización de Pesos: Los pesos se actualizan en función del gradiente y la tasa de aprendizaje.
- Iteración: Este proceso se repite para cada conjunto de datos en múltiples épocas hasta que el modelo converge.
Consideraciones Adicionales
- Regularización: Ayuda a evitar el overfitting añadiendo un término de penalización a la función de coste.
- Tasa de Aprendizaje (Learning Rate): Determina el tamaño de los pasos que da el algoritmo de descenso de gradiente. Es crucial ajustarla correctamente para asegurar la convergencia del modelo.
- Validación Cruzada: Divide el conjunto de datos en varios subconjuntos para evaluar el modelo de manera más precisa y evitar el overfitting.
Este proceso iterativo y detallado es fundamental para entrenar redes neuronales efectivas y precisas, permitiendo que las aplicaciones de IA con Python se implementen con éxito en diversos contextos.
Evaluación y Mejora del Modelo
Regularización y overfitting
La regularización ayuda a reducir el overfitting, que ocurre cuando el modelo se ajusta demasiado a los datos de entrenamiento y no generaliza bien en datos nuevos. Técnicas como Dropout y L2 regularization son comunes.
Normalización de datos
La normalización asegura que todas las entradas tengan una escala similar, lo que puede acelerar el proceso de aprendizaje y mejorar el rendimiento del modelo.
Ajuste de hyperparámetros: learning rate
El learning rate determina el tamaño de los pasos que da el algoritmo de descenso de gradiente. Un ajuste adecuado es crucial para la convergencia del modelo.
Ejemplo Práctico: Red Neuronal para Clasificación
Paso a paso del código en Python
A continuación, se presenta un ejemplo práctico de implementación de una red neuronal en Python utilizando TensorFlow y Keras:
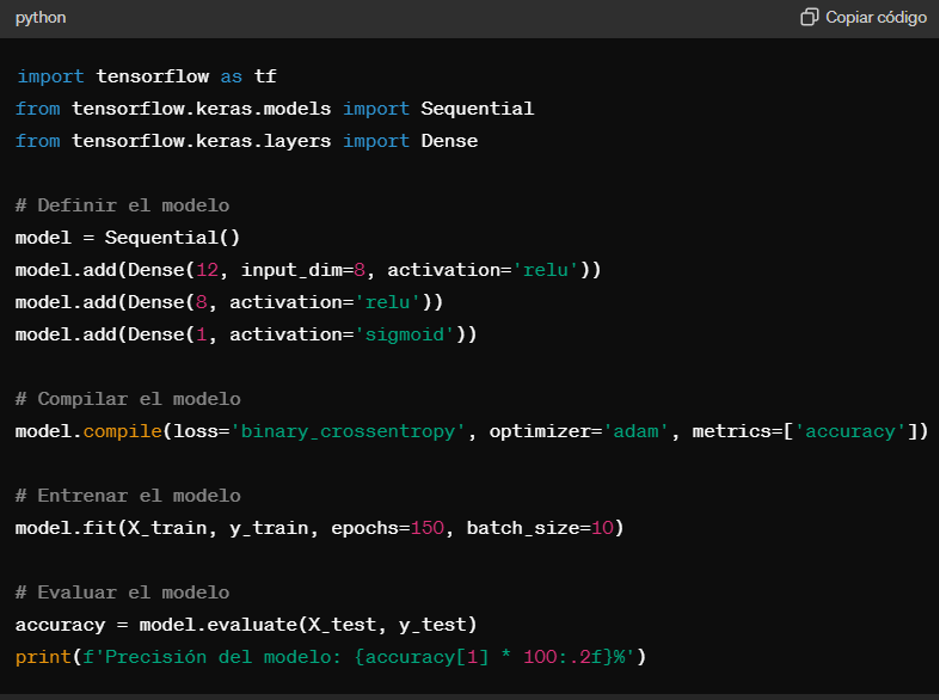
Análisis de resultados
Una vez entrenado el modelo, es importante evaluar su rendimiento en un conjunto de datos de prueba para asegurarse de que no ha sobreajustado los datos de entrenamiento.
Cómo usar modelos preentrenados para ahorrar tiempo y recursos en la construcción de nuevos modelos con transfer learning
El Transfer Learning (Aprendizaje por Transferencia) es una técnica en la que se utiliza un modelo previamente entrenado en una tarea similar y se adapta para una nueva tarea. Esto es especialmente útil cuando se dispone de una cantidad limitada de datos para entrenar el nuevo modelo. El objetivo es transferir el conocimiento adquirido en la tarea original al nuevo problema, permitiendo entrenar modelos más precisos y eficientes en menos tiempo.
Ventajas del Transfer Learning
- Reducción del tiempo de entrenamiento: Al aprovechar modelos preentrenados, se reduce significativamente el tiempo necesario para entrenar el modelo desde cero.
- Mejora del rendimiento: Los modelos preentrenados han sido entrenados en grandes conjuntos de datos y han aprendido características útiles que pueden mejorar el rendimiento en la nueva tarea.
- Requerimiento de menos datos: Es especialmente beneficioso en escenarios con pocos datos disponibles para entrenar un nuevo modelo desde cero.
Cómo Funciona el Transfer Learning
- Selección del modelo preentrenado: Se elige un modelo previamente entrenado en una gran base de datos, como ImageNet, que contiene millones de imágenes etiquetadas. Ejemplos de modelos populares incluyen VGG16, ResNet y Inception.
- Adaptación del modelo: Se eliminan o se modifican las capas finales del modelo preentrenado y se añaden nuevas capas que se ajusten a la tarea específica. Estas nuevas capas se entrenan desde cero.
- Ajuste fino (Fine-tuning): A veces, además de entrenar las nuevas capas, se permite que algunas de las capas preentrenadas se ajusten ligeramente para adaptarse mejor a la nueva tarea.
El Transfer Learning es una herramienta poderosa en el ámbito del aprendizaje profundo, especialmente en contextos donde los datos son limitados o se busca rapidez en el desarrollo del modelo. Es ampliamente utilizado en la clasificación de imágenes, procesamiento de lenguaje natural y otras áreas de inteligencia artificial. Incluir esta técnica en tu flujo de trabajo puede mejorar significativamente la eficiencia y efectividad de tus modelos.
La importancia de las redes neuronales en IA
En este tutorial, hemos explorado en profundidad el proceso de creación y entrenamiento de redes neuronales utilizando Python. Desde la instalación de herramientas esenciales como TensorFlow y Keras, hasta la implementación de un modelo práctico, pasando por el entendimiento de funciones de activación y técnicas de optimización como el descenso de gradiente y backpropagation, cubrimos todos los aspectos cruciales. Las redes neuronales son fundamentales en el desarrollo de aplicaciones avanzadas de IA, y con los conocimientos adquiridos, estás bien equipado para comenzar a construir y experimentar con tus propios modelos. ¡Continúa explorando y aprendiendo en el fascinante mundo de la inteligencia artificial!
Si deseas profundizar en este tema, te invitamos a descargar la guía que hemos preparado especialmente para ti:
¿Quieres impulsar tu carrera al siguiente nivel? ¡Abre puertas a grandes oportunidades con nuestros programas especializados en data! Con nuestros Máster en Data Analytics, Máster en Data Science, Máster en Data Analytics y Science, no solo te formarás, sino que te transformarás en un profesional altamente demandado en el campo del análisis de datos e inteligencia artificial
Nuestros programas están diseñados no solo para enseñarte, sino para equiparte con habilidades cruciales que te llevarán a alcanzar tus más ambiciosas metas profesionales. Aprenderás análisis estadístico, matemáticas, business intelligence con herramientas como Excel y Power BI, bases de datos y SQL, visualización de datos con Tableau, y dominarás Python, machine learning, deep learning y big data.
¡Tu futuro comienza aquí! Descubre cómo nuestros programas pueden transformar tu trayectoria.
Si te ha gustado este artículo y estás interesado en el mundo del análisis de datos, te invitamos a que descargues nuestros recursos PDF sobre extracción de datos en Python. ¡Es totalmente gratis! También puedes visitar nuestro blog para descubrir más artículos como este.


